Try out my SAGAN implementation
This article discusses self-attention generative adversarial networks, a new technique that improves the stability of generative adversarial networks and the quality of their samples. An orthogonal technique called spectral normalization is explained in this blog post.
Since generative adversarial networks were conceived four years ago, startling improvements in the quality and diversity of samples have been achieved. Much of this progress has come from stabilizing the adversarial game between the discriminator and the generator, which can collapse if the discriminator can differeniate real and fake examples too easily. Some notable papers about GAN stabilization include
- Improved Techniques for Training GANs , which introduces new tricks for stabilizing GANs as well as a metric to evaluate the quality of GAN samples, the Inception score.
- Wasserstein GAN, which puts forth theoretical justifications for using the a metric for which the generator always receives an appreciable gradient signal, regardless of how easily separable the fake and real distributions are.
- Improved Training of Wasserstein GANs, which enforces the K-Lipschitz regularization on the discriminator required by the Wasserstein metric in a more graceful and stable way—the gradient penalty.
- Spectral Normalization for Generative Adversarial Networks imposes this K-Lipschitz regularization while maintaining the capacity of the discriminator as much as possible. Moreover, whereas gradient penalty can only be enforced at a finite number of points in the data space, spectral normalization ensures that the discriminator is K-Lipschitz everywhere.
Many of the innovations above are agnostic to the problem where GANs are typically applied: image generation. In this setting, the generator is a deconvolutional neural network and the discriminator is a convolutional neural network. Typically, the discriminator is a series of local convolutional filters followed by nonlinearities, which successively downsample the image. The downsampling process terminates in a global average pooling, which compresses the activations to a single numeric output.
This average pooling treats distant points in the image as independent, which is certainly not the case in most natural images. For instance, suppose there is a real image in our training set

and our generator produces an output

In this case, the generator matches the true data exactly except at a small spatial position where the generator mistakenly produces a red box. If the discriminator is using global average pooling, then the outputs of distant receptive fields—which cannot differentiate the two images—will be averaged with the outputs of few receptive fields that do contain the red box.
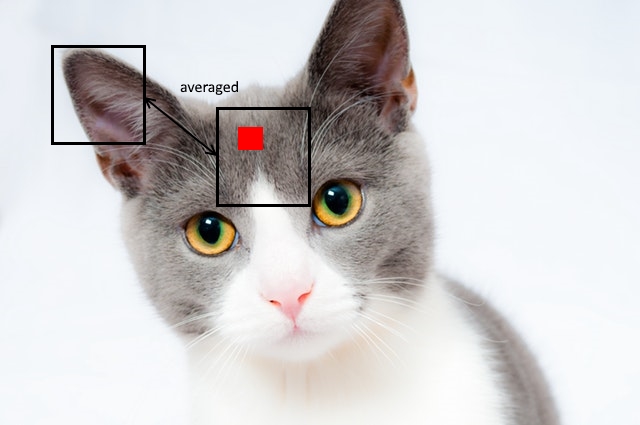
This averaging destroys the signal that the discriminator needs to differentiate the two images, making it difficult for the generator to improve further.
The independence assumption of global pooling (and direct linear layers as well) makes it difficult for the discriminator to detect errors in the global configuration of features—this is one reason why it has been difficult to generate high-quality ImageNet samples.
Non-local Neural Networks (Wang et al.) address the problem of CNNs processing information too locally by introducing a self-attention mechanism, where the output of each activation is modulated by a subset of other activations. This helps capture dependencies between distant parts of the images and allows the CNN to attend to smaller parts of the image if necessary.
Self-Attention Generative Adversarial Networks (SAGAN) apply this mechanism to the GAN discriminator, mitigating the problem above.
In a self-attention block, we temporarily ignore all spatial structure by flattening each channel into a single vector, after computing a local linear transformation on each pixel:
\begin{equation*} o_\text{self-attention} = \underbrace{\text{softmax}(\overbrace{x^T W_f^T}^{HW\times C}\,\,\overbrace{W_g x}^{C\times HW})}_{HW \times HW} \underbrace{W_h x}_{HW \times C} \end{equation*}
where \(H\) is the height, \(W\) is the width, and \(C\) is the number of channels in the self-attention layer.
The softmax attention output weighs the influence of distant outputs on the output at each position in the discriminator. This allows the discriminator to explicitly compare outputs at separated points in the image and, in addition, focus all of its attention on a specific location in the image.
The self-attention output is added to the original output and multiplied by a weight parameter. At the start of training, this weight is zero; as the generated samples become more difficult to distinguish from the real samples, this weight can be increased so that the discriminator can use self-attention.
 (
(The above self-attention visualizations from the SAGAN paper demonstrate how the attention units capture the object shape. In most cases, the attention maps capture local feature similarities (2nd from left, top) as a convolutional network would. However, in some cases (1st and second from right, top and bottom), the self-attention layer detects detects correlations between features in distant regions of the image. This explains why the global structure of SAGAN samples, seen above, looks so convincing. Below is an example of the self-attention maps from my implementation of SAGAN for the top-left-hand corner of the image.

Introducing the self-attention mechanism to GANs improves the quality of samples considerably: the authors of SAGAN report an Inception score of 52.52, an enormous improvement on the already impressive result of 36.8 achieved by spectral normalization a few months ago. This improvement in quality and diversity metrics is reflected directly in the quality of SAGAN ImageNet samples; many are indistinguishable from real images.
In my opinion, self-attention GANs reveal the potential to improve GANs by incorporating better priors into models (in this case, our prior is to explicitly build in modeling of non-local feature dependencies into some layers of the discriminator). This approach to improving GANs stands in contrast to more explored approach thus far: changing the GAN training objective or discriminator regularization. We have seen before with LapGAN and Progressive Growing GAN that carefully designed discriminator architectures (i.e., model priors) can lead to improved sample quality and diversity. With the breakthrough of self-attention GANs, we see this line of work confirmed yet again. It is only a matter of time that further improvements based on this strategy will come, and this already impressive state of the art will be beaten once again.